DeepSeek: 중국 AI의 새로운 전선이 업계 거인들을 충격에 빠뜨린다
2가지 획기적인 기술과 AI 거물들이 놀란 6가지 이유 살펴보기
2023년 사모펀드 High-Flyer Quant 가 설립한 AI 기업 DeepSeek은 짧은 역사에도 불구하고 빠르게 AI 분야의 초점이 되었습니다. 이 회사의 최신 혁신인 DeepSeek-V3 모델은 인상적인 6,710억 개의 매개변수를 자랑하며 성능과 비용 효율성의 균형을 위한 새로운 벤치마크를 설정했습니다. 하지만 DeepSeek을 진정으로 돋보이게 하는 혁신은 무엇일까요?

저비용의 2가지 핵심 기술
DeepSeek은 2년 만에 557만 달러의 비용으로 고성능 AI 모델을 개발하는 데 성공했는데, 이는 OpenAI의 GPT-4 훈련 비용 6,300만 달러와 대조적이며, GPT-5의 예상 예산 5억 달러보다 훨씬 낮습니다. 이러한 성과는 다음과 같은 혁신적 기술 덕분에 가능했습니다.
- "뇌세포"의 선택적 활성화MLA(Multi-head Latent Attention): KV 캐시를 줄여 효율적인 추론을 보장하는 더 빠르고 더 나은 주의입니다.
- DeepSeekMoE(전문가 혼합) : 희소 계산을 통해 경제적 비용으로 강력한 모델을 훈련할 수 있는 새로운 희소 아키텍처입니다.
- DeepSeek-V3는 "전문가 혼합(Mixture of Experts)" (MoE) 아키텍처라는 디자인을 채택했습니다. 간단히 말해서, 필요할 때 모든 "뇌 세포"를 활용하는 대신 일부만 활성화합니다. 이를 통해 컴퓨팅 리소스 소비가 크게 줄어들어 2,048개의 NVIDIA H800 GPU만 사용하여 모델을 학습할 수 있습니다.
- 데이터 처리 및 에너지 효율성 혁신
DeepSeek은 고품질의 학습 데이터를 생성하기 위한 내부 도구를 개발했으며 " 증류 기술 "을 사용하여 계산 리소스 요구 사항을 더욱 줄입니다. 학습 프로세스 동안 FP8 기술이 활용됩니다. 이는 효율성을 개선하는 동시에 메모리 요구 사항을 크게 줄이는 저정밀도 데이터 형식입니다. FP8을 사용하면 계산 성능을 저하시키지 않고도 기존 FP16 기술에 필요한 메모리 요구 사항의 절반으로 메모리 요구 사항을 줄일 수 있습니다.
기술 거대 기업이 놀란 6가지 이유
DeepSeek의 기술을 살펴본 후, 이 기술이 업계에 큰 반향을 일으킨 이유를 알아보겠습니다.
1. 낮은 비용과 높은 효율성
DeepSeek의 개발은 불과 2개월과 약 550만 달러로 OpenAI와 Google과 같은 거대 기업이 유사한 모델을 개발하는 데 사용한 수십억 달러의 일부에 불과했습니다. 이 빠르고 효율적인 개발 방식은 대규모 언어 모델(LLM)을 만드는 데 대한 장벽이 상당히 줄어들고 있음을 보여줍니다.
2. 경쟁력 있는 성과
타사 벤치마크에 따르면 DeepSeek의 성능은 특정 도메인에서 OpenAI와 Meta의 최첨단 모델과 동등하거나 더 뛰어납니다. 이는 고성능 모델을 달성하는 데 더 이상 막대한 재정 투자가 필요하지 않음을 증명합니다.
3. 하드웨어 제한 사항 깨기
DeepSeek은 NVIDIA H800 칩을 사용하여 모델을 훈련했습니다. 이 칩은 H100보다 성능이 낮지만 접근성이 더 좋은 버전입니다. 이 접근 방식은 하드웨어 비용을 절감할 뿐만 아니라 H100 칩과 관련된 공급 제약도 피했습니다.
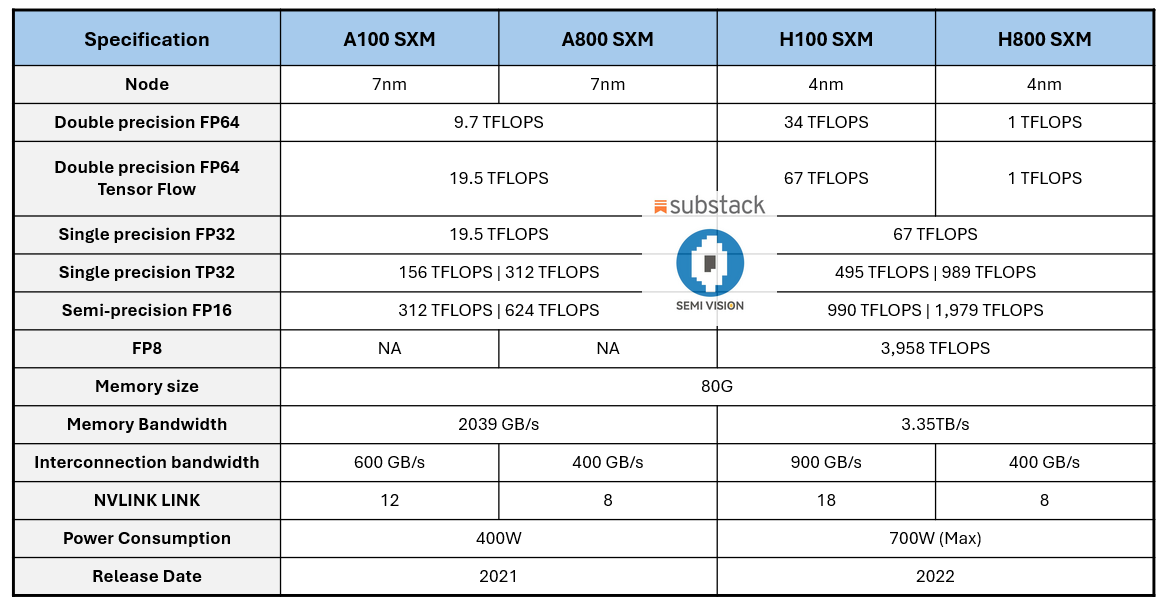
- 대형 모델의 전장
A800은 "트리밍"된 후 대형 모델 학습의 효율성을 떨어뜨렸습니다. A800 SXM은 주로 GPU 카드 간의 데이터 전송 효율성이 떨어져 대역폭이 33% 감소했습니다. 예를 들어, 1,750억 개의 매개변수가 있는 GPT-3와 같은 모델을 학습할 때 여러 GPU가 함께 작동해야 합니다. 대역폭이 부족하면 성능이 약 40% 떨어질 수 있습니다(GPU가 데이터가 도착할 때까지 대기하기 때문). A800과 H800의 비용 효율성을 고려할 때 중국 사용자는 여전히 A800을 선호합니다. 그러나 A800과 H800의 학습 효율성이 낮아진 것은 카드 간에 일부 학습 데이터를 교환해야 하기 때문이며, 전송 속도 감소는 효율성에 직접적인 영향을 미칩니다. - HPC 분야에서
이중 정밀도 컴퓨팅 측면에서 A800과 A100은 동일한 계산 능력을 가지고 있으므로 고성능 과학 컴퓨팅에는 영향이 없습니다. 그러나 H800의 상황은 훨씬 더 나쁩니다. 이중 정밀도 컴퓨팅 능력이 단 1 TFLOPS로 줄어들어 거의 사용할 수 없게 되었습니다. 이는 슈퍼컴퓨팅 분야에 상당한 영향을 미칩니다.
4. 시장 지배력에 도전하다
DeepSeek의 등장은 OpenAI, Google, Meta와 같은 AI 리더의 지배력이 새로운 경쟁자에 의해 붕괴될 수 있다는 신호입니다. 이는 기존 산업 거인들에게 중요한 경종으로 작용합니다.
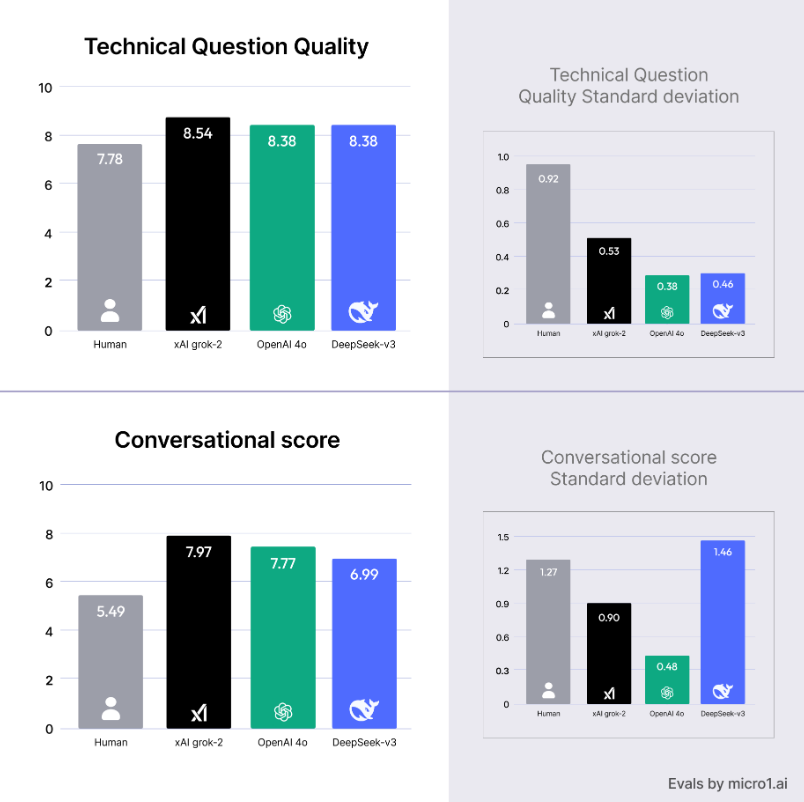
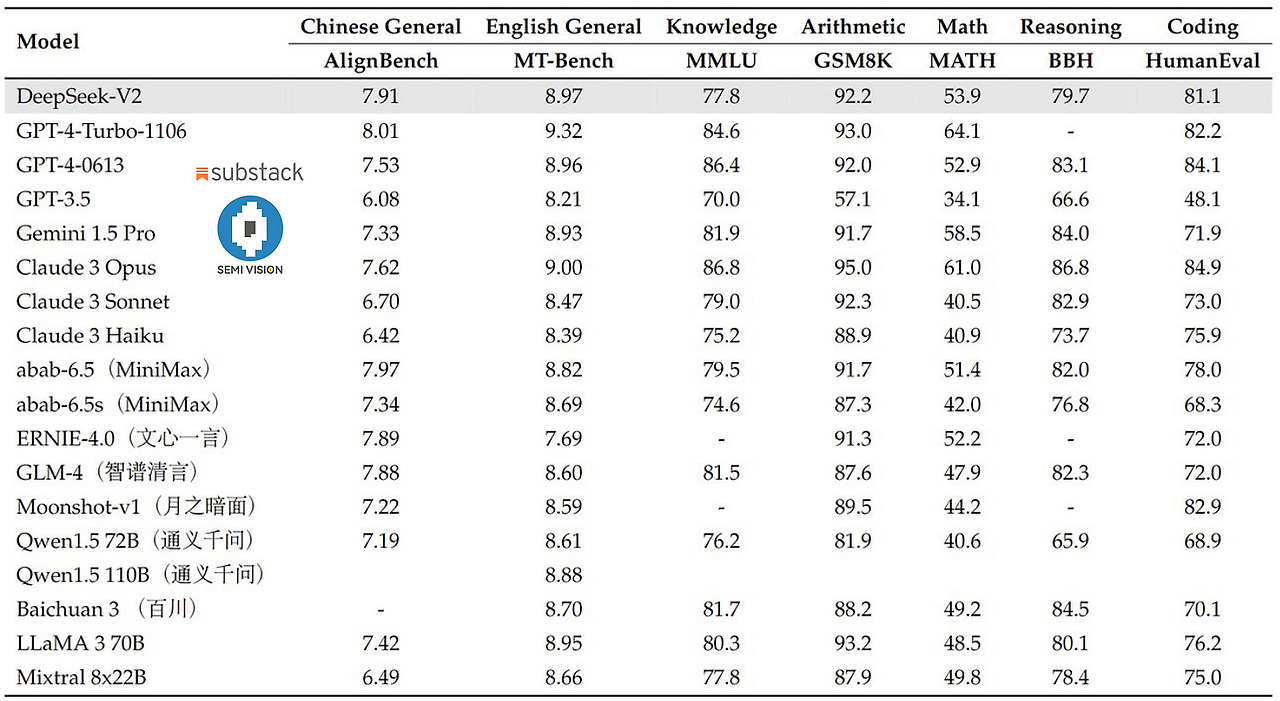
5. 투자자를 위한 새로운 관점
DeepSeek의 성공은 투자자들이 값비싼 최첨단 모델 훈련에 계속 자금을 지원해야 하는지, 아니면 훨씬 낮은 예산으로 비슷한 결과를 얻을 수 있는지 재고하게 만들었습니다. 이는 자본의 흐름을 바꾸고 시장 질서에 심오한 영향을 미칠 수 있습니다.
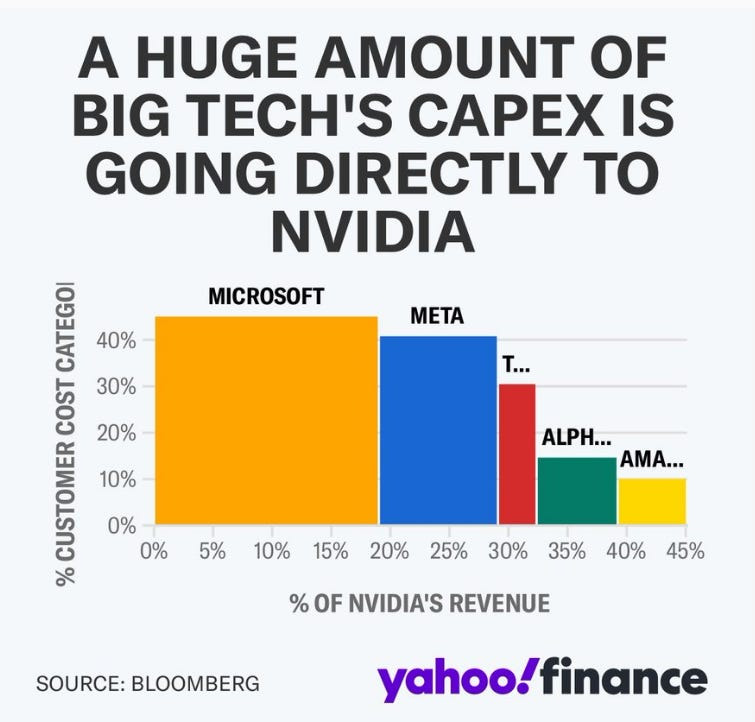
차트는 NVIDIA 수익 중 주요 기술 기업의 CAPEX 투자에서 발생하는 비율을 보여줍니다.
- Microsoft는 NVIDIA의 가장 큰 고객 중 하나로, 상당 부분을 차지합니다.
- 메타 역시 상당히 기여하고 있으며, 그 뒤를 다른 회사들이 따르고 있습니다.
- Alphabet(Google) 과 Amazon의 점유율은 Microsoft와 Meta에 비해 규모는 작지만 주목할 만한 수준입니다.
기술 거대 기업은 AI 워크로드, 데이터 센터 운영 및 기타 고급 컴퓨팅 요구 사항에 대해 NVIDIA의 GPU 및 관련 제품에 크게 의존합니다. " 더 많이 살수록 더 많이 절약할 수 있습니다 " 라는 문구 는 이러한 회사가 AI 및 컴퓨팅 인프라를 구축하는 동안 비용을 최적화하기 위해 대량 구매를 활용하고 있음을 시사합니다.
중국의 AI 개발을 위한 독특한 경로
중국 시장은 세계에서 가장 큰 데이터 리소스를 자랑하지만 기술 금수조치와 하드웨어 공급 부족과 같은 요인으로 인해 하드웨어 계산 능력에 어려움을 겪고 있습니다. 이로 인해 중국 AI 회사는 효율성 최적화에 더 많은 중점을 두게 되었습니다. DeepSeek의 성공은 리소스 사용과 성능 간의 새로운 균형점을 보여줍니다.
한편, Google, Microsoft, Meta와 같은 기술 거대 기업은 에너지 집약적인 AI 교육 요구를 지원하기 위해 핵 에너지에 베팅하고 있습니다. 반면, DeepSeek와 같은 신흥 기업은 다른 경로를 선택하여 자원 낭비를 최소화하고 업계에 새로운 관점을 제공하기 위한 기술 혁신에 집중하고 있습니다.
DeepSeek의 스토리는 AI 경쟁의 미래가 기술 자체에 관한 것이 아니라 제한된 리소스로 최상의 결과를 달성하는 것에 관한 것임을 보여줍니다. 이러한 접근 방식은 시장에서 게임의 규칙을 바꾸는 열쇠가 될 수 있습니다.
중국의 최고 AI 모델 및 스타트업 9개
- 바이두 - Ernie 4.0
- 알리바바 클라우드 - Qwen 2
- ByteDance — 두바오
- 텐센트 - 훈위안
- Moonshot AI — Ohai, Noisee, Kimi
- 미니맥스 — 토키
- 콰이쇼우 — 클링
- iFlytek — 스파크 V4.0
- 지푸 AI
'반도체' 카테고리의 다른 글
| 삼성은 왜 TSMC를 따라잡지 못할까? (1) | 2025.01.27 |
|---|---|
| SK하이닉스 HBM4 AI 칩에서 가장 비싼 필수품 (0) | 2025.01.27 |
| 반도체 패키징 하이브리드 본딩(Hybrid Bonding) 설명 (0) | 2025.01.27 |
| Dram의 미세공정 측정분야(CD SEM)의 도전과 어려움 (0) | 2025.01.03 |
| 책추전 'TSMC 세계1위의 비밀' 린훙원지음 (0) | 2024.12.07 |